I've been learning about natural language processing and machine learning. The current state of the art ways of working with natural language use various forms of embeddings. This has been true for a long time; even word2vec is an embedding. But now we have much more sophisticated embeddings that are trained while training transformer models.
My wife's most cited paper is on ConceptNet, a way of extending word embeddings across multiple languages. But it was from 2017, predating the transformer by only 2 months.
Now there are multilingual embedding models. Let's play with one.
Simple Test
Here's our experiment.
- Let's take some sentences in a few languages.
- Some of these languages should have similar meanings.
- We'll take their embeddings under a multilingual sentence transformer.
- Then we'll look at their cosine similarities.
(Modern libraries are so expressive that it's almost exactly as hard to write the code itself; except plotting, which is always hard).
import numpy as np
from sentence_transformers import SentenceTransformer
# My current favorite multilingual model
model = SentenceTransformer('BAAI/bge-m3')
sentences = [
"this is a test",
"this is also a test",
"this was a test",
"something completely different",
"hola, como estas?",
"hi, how are you?",
"como va?",
"jak się masz?"
]
embeddings = model.encode(sentences)
normed = embeddings / np.linalg.norm(
embeddings, axis=1, keepdims=True
)
similarity_matrix = np.dot(normed, normed.T)
# print(similarity_matrix)
# informative, but also just numbers.
# instead we visualize the matrix.
fig = plot_similarity_matrix(mat) # code at end
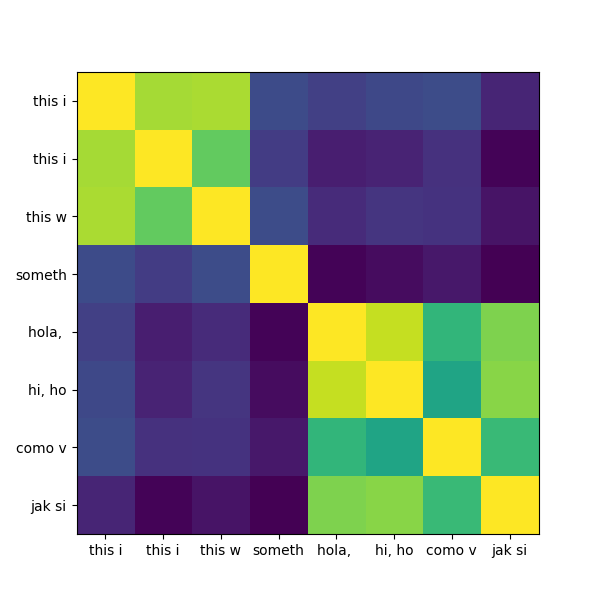
In short, that's amazing. This example is sort of silly, but coherence even on a "silly" example is remarkable.
Static Model Comparison
I'm working on a project where I can't afford the computational expense of running everything through a sentence embedding, but I want some of the information. One of the best parts about word2vec is that it's sooooo fast and easy to compute. Transformers are great, but they're resource hungry.
I needed something faster. Then I learned about Static Embedding Models. In short, they
- Take a good transformer,
- Compute the embedding of every output token from that transformer,
- Save those into a big matrix,
- Take the mean embedding of the tokenizations of any future input.
This morally makes embedding into an easy tokenization followed by a matrix multiplication — blazingly fast. How does it do on the same task?
I use model2vec, my current favorite static embedding library.
# same namespace as above
from model2vec import StaticModel
model = StaticModel.from_pretrained(
"distilled-BGE-M3-using-model2vec.model"
)
# same code
embeddings = model.encode(sentences)
normed = embeddings / np.linalg.norm(
embeddings, axis=1, keepdims=True
)
similarity_matrix = np.dot(normed, normed.T)
fig = plot_similarity_matrix(similarity_matrix)
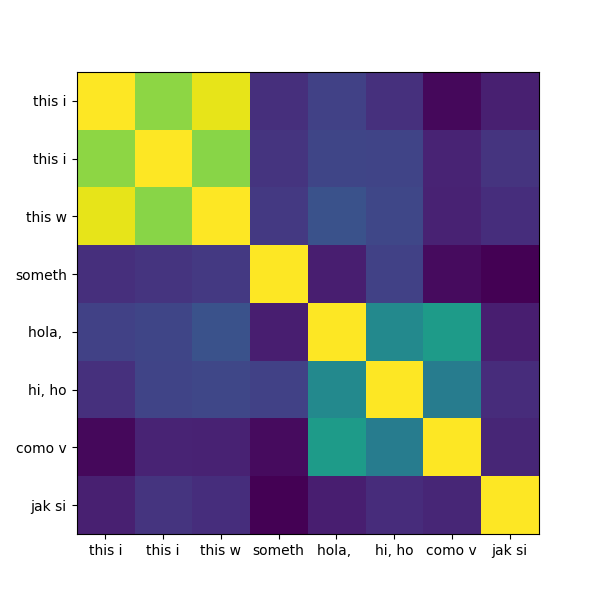
What do we notice? The three similar English phrases in the top left remain strongly coherent. The Spanish and English "how are you" phrases are recognized as similar. But now Polish is large lost in relation to the other languages.
I hadn't expected this difference when I was coding up the example. This shows there are sometimes large differences in behavior. When looking for positive matches, the speed of static embeddings and the often close behavior provides strong incentive for use.
Appendix: plotting code
I include it for completeness. It's not beautiful.
import matplotlib.pyplot as plot
def plot_similarity_matrix(mat):
fig, ax = plt.subplots(figsize=[6, 6])
ax.imshow(mat)
ax.set_yticks(np.arange(len(sentences)))
ax.set_yticklabels(
[sentence[:6] for sentence in sentences]
)
ax.set_xticks(np.arange(len(sentences)))
ax.set_xticklabels(
[sentence[:6] for sentence in sentences]
)
return fig
Leave a comment
Info on how to comment
To make a comment, please send an email using the button below. Your email address won't be shared (unless you include it in the body of your comment). If you don't want your real name to be used next to your comment, please specify the name you would like to use. If you want your name to link to a particular url, include that as well.
bold, italics, and plain text are allowed in
comments. A reasonable subset of markdown is supported, including lists,
links, and fenced code blocks. In addition, math can be formatted using
$(inline math)$ or $$(your display equation)$$.
Please use plaintext email when commenting. See Plaintext Email and Comments on this site for more. Note also that comments are expected to be open, considerate, and respectful.
Comments (1)
2026-01-26 David
This also marks my intent to return to writing publicly. I plan on writing something approximately once a week, possibly with heavy amortization. We'll see!